

第二章其实没什么好写的,比较基础,只是在此基础上添加了论文依据,以及很多的更加详细的拓展说明。
对于简单的GPU渲染管线的介绍,可以看我的另一个博客专栏:GPU渲染管线流程
这里就简单说说。
2.1 架构
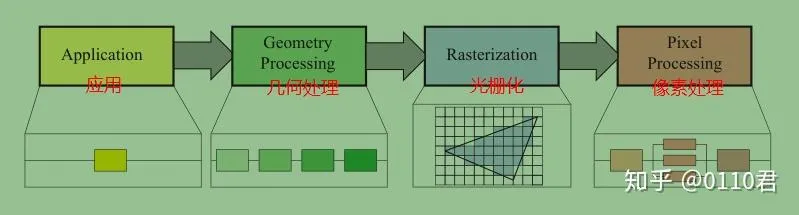
管线的使用允许了我们的GPU可以并行的去处理大量的数据。管线的设置就是让每个阶段把自己的输出传到下个阶段的当输入的这么一个流程。而书中把渲染管线分成了四个大阶段,每个阶段内部都有着自己的管线:
- 应用阶段(CPU): 从渲染上看,很多的操作例如碰撞检测,动画,物理等都是在这个阶段去处理的,主要是把顶点和变换数据塞给下个阶段
- 几何处理阶段(GPU): 这个阶段处理顶点的变换和投影,来决定顶点最终的位置
- 光栅化阶段(GPU): 这个阶段是把上个阶段传进来的顶点变成三角形,并且填充像素
- 像素处理阶段(GPU): 这个阶段对渲染目标上的每个像素去进行着色的处理来决定显示在屏幕上的最后的颜色
2.2 应用阶段
应用阶段的最终目标就是把几何处理阶段应该要拥有的输入传过去,例如顶点信息等。一般来说这里并不会有一个切确的子管线,因为它涵盖的范围也确实很大。
这就包括了去处理我们的硬件输入,例如键盘鼠标等,一直到碰撞的反馈。可以理解为一个引擎在进入Shader前的所有的跟渲染数据相关的准备工作都算是应用阶段的一部分,包括我们对物体的动态的变换控制等。不过现在很多的操作在架构上是可以在GPU侧用计算着色器去处理的。很多加速的算法都要在这里去处理,比如说视锥体剔除。类似的操作可以在CPU侧让整个Draw Call的次数减少来提高整体的效率。
2.3 几何处理阶段
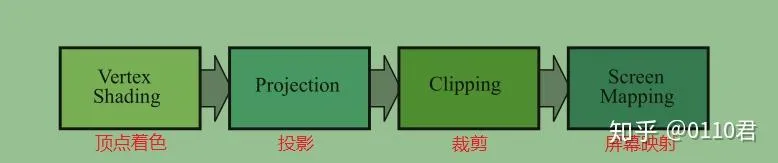
几何处理阶段内部的管线在书里被细分成下面几个阶段:
- 顶点着色
- 投影
- 裁剪
- 屏幕映射
2.3.1顶点着色
顶点着色阶段是负责把我们输入的所有的顶点坐标通过变换去设置位置的一个阶段。不过顶点着色这里并不单纯是去调整顶点的位置,同时我们也会对很多顶点的其他信息进行操作,例如颜色、法线、纹理坐标等。在一些比较旧的渲染管线的实现里,我们会在顶点着色阶段把光照结果算上,这样在光栅化的时候就可以通过插值算出每个像素大概的一个颜色。
一般来说我们输入的顶点会处于一个物体本身的本地坐标,在这个阶段我们需要把顶点从本地坐标移动到世界坐标上。一般我们会在这个阶段为每个物体准备一个Model Transform的矩阵,用于把物体内部的所有顶点从Model Space转换到World Space
可选顶点处理
虽然书上把这些阶段放在投影后,但好像在顶点着色后更合理一些。
在上面的阶段完成之后,我们就有足够的数据去进行接下来的光栅化。不过顶点着色本身有一个限制就是我们没有办法去建立新的顶点,这样有很多的效果是没有办法达到的。所以我们也可以在渲染管线中可选性的添加下面三个阶段:曲面细分、几何着色、Stream Output
要注意的是,在不使用曲面细分和几何着色的时候,顶点着色阶段掌控着对世界坐标的转换。但假设我们要使用这些可选阶段,那么为了方便处理我们的顶点着色阶段并不适合进行空间变换,而是只能单纯的输入原始的模型空间的顶点数据。
曲面细分 Tessellation
曲面细分的本质就是通过在顶点着色后已有的图元(比如三角形)信息,去在图元内部生成新的图元。通过这个功能,我们可以( 出自DX12龙书 ):
- 进行基于GPU的LOD处理
- 更简单的处理物理和动画(用原始的控制点处理物理和动画,然后通过曲面细分去完善物体细节)
- 节约内存的使用
在我们需要渲染一个球的时候,我们需要面临的一个很大的问题就是球体需要使用的顶点的数量。如果我们选取较少的顶点,远处看的时候并不会有瑕疵,而且开销比较低,不过近看的话球表面的边角会过于显眼。 如果我们选取大量的顶点,那么在渲染较远的球体的时候实际上会有很多的开销是没必要的。这个时候我们需要一个比较合理的LOD的解决方式,很明显在CPU端去通过摄像机和物体去决定输入的顶点数量是比较不明智的,但曲面细分阶段在GPU侧解决了这个问题。
在曲面细分的阶段实际上也包含了 Hull Shader和Domain Shader ,这里不细讲。
拿球的LOD来说,实际的使用流程就是把一个球的最低需要的顶点数量传入顶点着色器,然后顶点着色器直接把那些顶点转发给曲面细分阶段。曲面细分阶段会根据摄像机距离决定细分多少,在分完顶点后再进行空间变换。
几何着色
几何着色器跟曲面细分是比较像的,都是去建立新的顶点。不过几何着色器并不是在已有的三角形上面建立新的顶点去细分已有的图元,而是在外部生成额外的顶点。几何着色器的输入可以只是一个点,或是一条线。
比较会用到的地方就是我们的粒子模拟的部分,一般模拟粒子的时候都是生成一大堆点,然后传入几何着色器再把点一个个的绘制出形状。
Stream Output
这个阶段比较特殊,他不是对顶点的额外处理。这个阶段是说我们可以把处理过后的顶点信息导出储存成在一个数组,并且后续可以在CPU/GPU读取这些数据。
2.3.2投影
投影在这里只是理论上把世界空间的顶点投影到裁剪空间的一个过程。
无论是在顶点着色器把图元移动到世界空间,还是在曲面细分/几何着色阶段把图元移动到世界空间,我们最后都需要用一个摄像机去把物体从世界空间拉到裁剪空间。
如果我们不使用曲面细分等功能,那么我们可以在顶点着色阶段投影,反之如果使用曲面细分/几何着色,那么会在传入光栅化前的那一个阶段投影。
我们可以通过透视投影/正交投影去决定摄像机看顶点的方式,然后通过这个去建立一个 View Matrix ,让我们世界空间中的顶点全部转化为裁剪空间的顶点。一般在投影之后我们的所有应该被渲染的顶点都会处于裁剪空间中,并且如果除以w 分量就会变成 NDC坐标(Normalized Device Coordinate) 中,也就是在 [-1,1]^3^ 的空间中。现在的API不会马上去进行一个转换(用户也不应该在顶点着色器转),而是在裁剪之后再转到NDC空间。
- 注意:在DirectX里,NDC的z轴范围为[0,1] *
2.3.3裁剪
在我们进行投影之后会有很多的图元跑到我们的裁剪空间的外面,这一个步骤就是把那些图元丢弃。有的三角形会有一部分的顶点在投影内,一部分在投影外,对于这些三角形我们会把这些三角形截断在裁剪空间内。并且在裁剪空间的边缘去建立新的顶点(值为即将被抛弃的顶点和空间内顶点的插值)。
2.3.4屏幕映射
屏幕映射阶段就是把我们裁剪后的所有顶点映射到屏幕空间。
拿分辨率800*600的显示来说,就是把**[-1,1]^2^范围的XY坐标转换到[0,800] [0,600]的屏幕坐标, 如果使用的是OpenGL这种使用 [-1,1] 作为Z**轴范围的,则需要转化成 [0,1] 的范围。
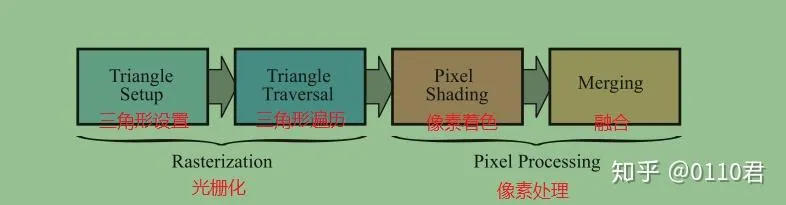
2.4 光栅化阶段
光栅化阶段的主要功能就是根据上面几何处理阶段的结果,去得到所有应该在屏幕上出现的像素,这里只是找到每个像素所对应的基本信息 (属于哪个三角形,和插值后的数据) ,并不考虑实际的决定像素最终的颜色。光栅化主要分为两个部分:
- 三角形设置
- 三角形遍历
2.4.1三角形设置
设置阶段主要是去计算一些三角形表面相关的数据,主要是方便接下来进行三角形遍历,以及接下来方便计算几何阶段传过来的顶点之间的差值。
2.4.2三角形遍历
三角形遍历阶段主要是在检查有哪些像素被三角形所覆盖。并且同时为这些被覆盖的像素准备好几何着色阶段的数据的插值。接下来会把这些像素的信息发送给像素处理阶段去决定最后出现在屏幕上的颜色。
2.5 像素处理阶段
像素处理阶段分为两个子阶段:
- 像素着色
- 合并
2.5.1 像素着色
像素着色阶段使用了之前计算好的差值当输入,并且会输出最后出现在屏幕上的颜色。一般来说我们会在这里去进行每个像素的一个光照的计算,并且大多时候会对额外的贴图进行采样。经过采样和计算就能得到我们期望这个像素显示在屏幕上的颜色,并且会把颜色传入到下一个阶段。
2.5.2 合并
由于我们的整个渲染管线是并行去进行的,这意味着在我们会同时处理大批的三角形。GPU会管理一个颜色缓冲来储存屏幕应该显示的所有像素的颜色,并且在我们进行像素着色后,数据并不会马上被写入这个颜色缓冲,而是要先经过合并阶段的处理。
一般在合并的时候我们会考虑到三个阶段【 按照顺序来的 】:
- 模板测试: 模板测试会根据我们维护的一个模板缓冲去决定哪些像素应该被绘制。
- 深度测试: 如果有多个三角形共享着同一个像素,那么我们会在一个像素内有多个着色的结果。深度测试可以决定我们希望存在颜色缓冲的是离得近的还是离得远的像素。
- 混合: 如果渲染中有考虑到有透明度的物体。那么我们可以在混合阶段决定半透明的物体应该怎么去和已有的颜色缓冲混合。
2.6 总结
这个管线是几十年来针对实时渲染应用程序的API和图形硬件发展的结果。
重要的是要注意这不是唯一可能的渲染管线;离线渲染管线经历了不同的演化过程 。电影制作的渲染通常是通过 微多边形管线 [micropolygon pipelines]完成的[289, 1734],但 光线追踪 [ray tracing]和 路径追踪 [path tracing]最近占据了主导地位。这些技术,包括在第11.2.2节,也可用于建筑和设计的视觉化[previsualization]。
NOTE在2026年的今天,光线追踪和路径追踪也不再是新奇玩意,3DGS(3D高斯泼溅)和NeRF(神经网络渲染)占据了更大的离线渲染市场。
多年来,应用程序开发人员使用这里描述的流程的唯一方法是通过使用图形API定义的固定功能管线 [fixed-function pipeline]。固定功能管线之所以这样命名,是因为实现它的图形硬件由不能灵活编程的元素[elements]组成。最后一个固定功能的大型游戏机是任天堂的Wii,它于2006年推出。可编程GPU的另一方面,GPU可以准确地确定在整个管线的各个子阶段应用了哪些操作。对于该书的第四版,我们假设所有的开发都是使用可编程GPU完成的。
2.7 进一步阅读及参考资料
布林[Blinn]的书《沿着图形管道的一段旅程》[A Trip Down theGraphics Pipeline] [165]是一本关于从零开始编写软件渲染器[software renderer]的旧书。 对于学习实现渲染管线的一些细微之处,这是一个很好的资源,讲解裁剪[clipping]和透视插值[perspective interpolation]等关键算法 。古老的(但经常更新的)OpenGL编程指南OpenGL Programming Guide[885] 提供了关于图形管线及其使用相关算法的详细描述。 我们书的网站, 提供了各种管线图的链接,渲染引擎实现等等 。